Knowledge Graph Generation
Introduction
The Knowledge Graph Generation project aimed to extract RDF triplets from economic documents, converting unstructured text into structured knowledge. This task was part of my coursework at ENSEIRB-MATMECA, where I worked with 3 other students on transforming economic articles into knowledge graphs, enabling deeper semantic analysis. The extracted knowledge graphs reveal relationships between key entities and attributes in the economic domain, using the Resource Description Framework (RDF) format. This project provided practical experience in working with cutting-edge techniques in natural language processing (NLP) and knowledge representation.
Concept and Approach
The task involved building a pipeline to automatically extract <subject-predicate-object> triplets from economic documents. These triplets represent relations between entities, forming the basis for creating a knowledge graph.
I used two Python scripts to implement the pipeline: one for data extraction and triplet generation, and the other for cleaning and refining the results. The pipeline relied on pre-trained models like mRebel and All-MiniLM for relation extraction and semantic similarity comparison. The extracted RDF triplets were saved in a knowledge base, making it easier to query and analyze relationships between various economic concepts.
Technical Solution
The project followed a detailed pipeline:
- Text Extraction: Text was extracted from economic PDFs using PyMuPDF.
- Relation Extraction: I used mRebel, a transformer-based model, to extract <subject-predicate-object> relations from the text, identifying key relationships.
- Entity Merging: All-MiniLM was employed to merge similar entities by comparing their vectorized representations and applying a similarity threshold to reduce duplicates.
- Triplet Generation: The pipeline generated RDF triplets that formed the basis of the knowledge graph, representing entities and their relationships.
- Graph Generation: I used PyGraft and rdflib to build the knowledge graph from the extracted triplets, visualizing relationships between entities.
- Data Storage: The triplets were stored in Memgraph, enabling efficient querying and management of the knowledge graph.
- Frontend & Visualization: A Streamlit interface allowed users to upload PDFs and interact with the generated knowledge graph through an intuitive web application.
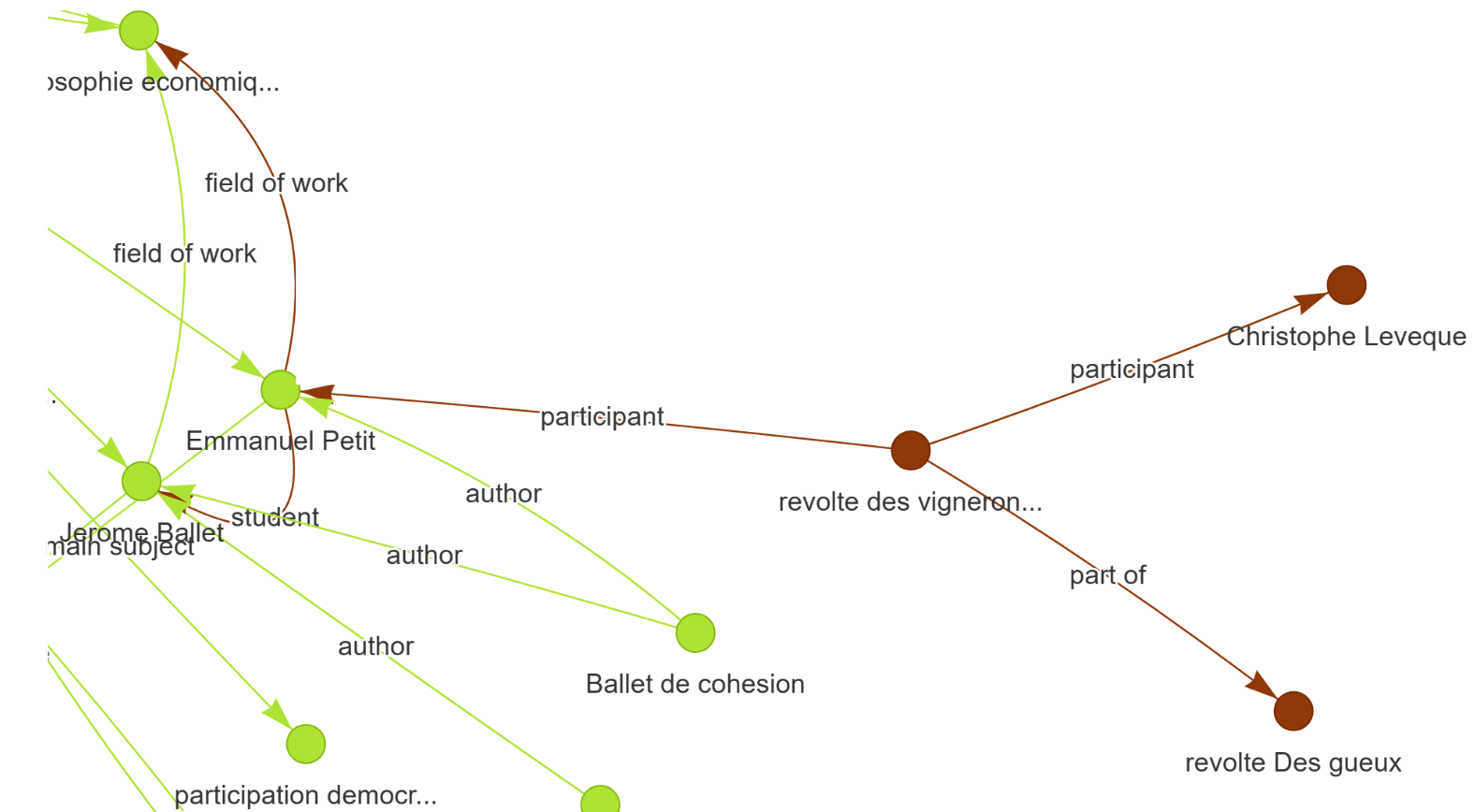
Short portion of the graph representing concepts and their relations.
Challenges and Solutions
One of the main challenges I faced was scaling the triplet extraction process while maintaining accuracy. Fine-tuning the models on specific economic text data improved the relevance of the extracted relations. Additionally, storing the knowledge base in a scalable and accessible format posed difficulties, which I addressed by experimenting with different graph database solutions.
Another hurdle was ensuring high-quality merging of entities with similar meanings. The merging process used All-MiniLM, which creates vectorized representations of concepts. By calculating the semantic similarity between entities, I could determine how closely related they were. A threshold cap was applied to these similarity scores, allowing the program to decide whether two entities should be merged based on how similar their vectorized representations were. This ensured that entities with similar meanings were properly combined, improving the overall quality of the knowledge graph.
Conclusion and Future Directions
This project demonstrated how powerful knowledge graphs can be for understanding complex economic relationships. Extracting structured information from unstructured text opens up new possibilities for data analysis and querying in the economic domain. Moving forward, there is room to improve both the scalability of the system and the accuracy of entity alignment and relation extraction.